Overview
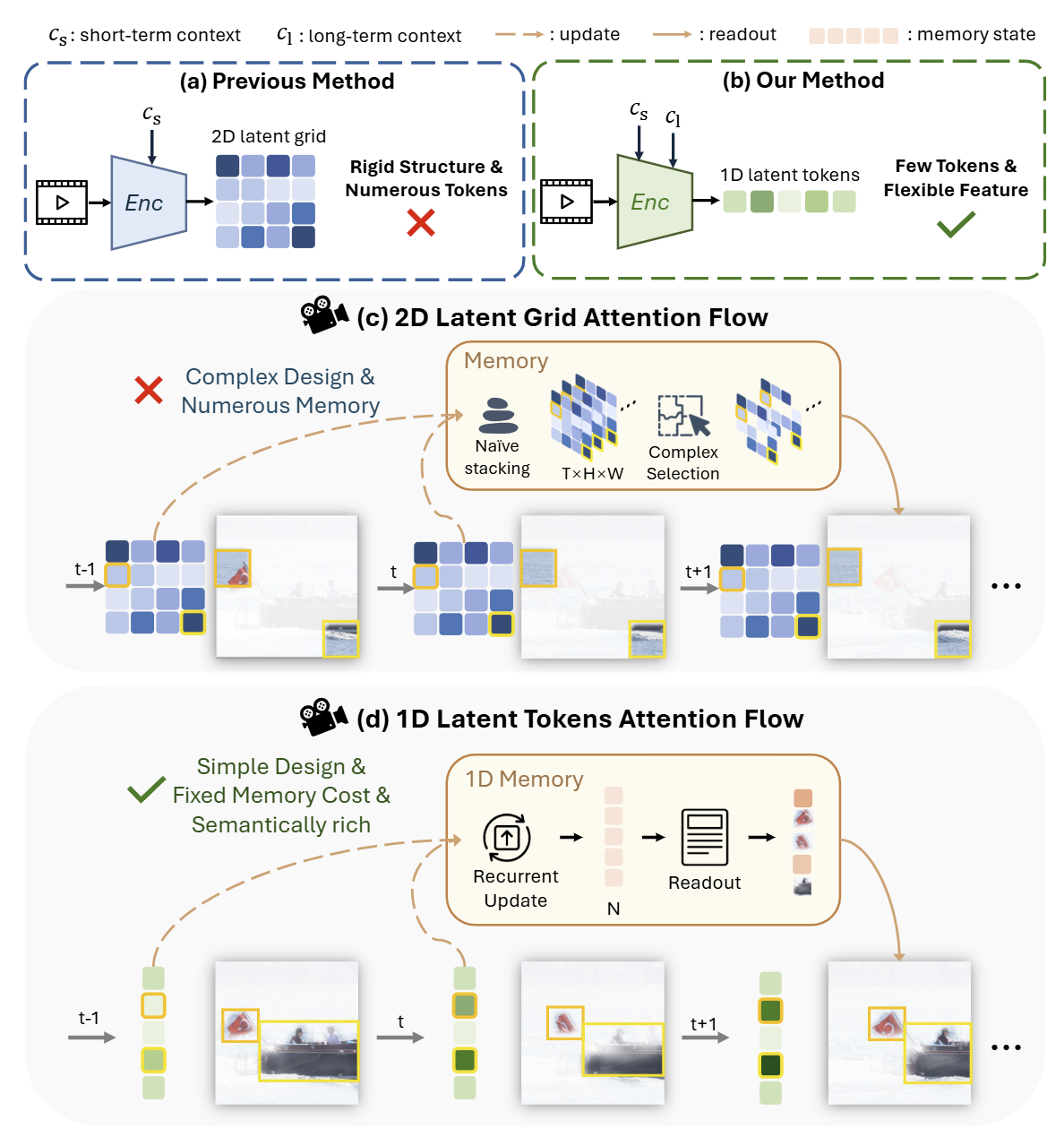
Previous generative video codecs encode videos into dense 2D latent grids with rigid spatial structures using short-term context, resulting in numerous inflexible tokens. Our method exploits both short-term and 1D-based long-term context to encode videos into a few flexible 1D latent tokens.
- 2D latent grids preserve fixed spatial correspondences between tokens and image patches, limiting redundancy exploitation and requiring complex memory designs.
- Our 1D latent tokens adaptively attend to semantic regions, while the 1D memory, managed by a few 1D tokens, efficiently preserves long-term context in a semantically coherent and computationally efficient manner.
Abstract
Recent advancements in generative video codec (GVC) typically encode video into a 2D latent grid and employ high-capacity generative decoders for reconstruction. However, this paradigm still leaves two key challenges in fully exploiting spatial-temporal redundancy: Spatially, the 2D latent grid inevitably preserves intra-frame redundancy due to its rigid structure, where adjacent patches remain highly similar, thereby necessitating a higher bitrate. Temporally, the 2D latent grid is less effective for modeling long-term correlations in a compact and semantically coherent manner, as it hinders the aggregation of common contents across frames. To address these limitations, we introduce Generative Video Compression with One-Dimensional (1D) Latent Representation (GVC1D). GVC1D encodes the video data into extreme compact 1D latent tokens conditioned on both short- and long-term contexts. Without the rigid 2D spatial correspondence, these 1D latent tokens can adaptively attend to semantic regions and naturally facilitate token reduction, thereby reducing spatial redundancy. Furthermore, the proposed 1D memory provides semantically rich long-term context while maintaining low computational cost, thereby further reducing temporal redundancy.
Methods
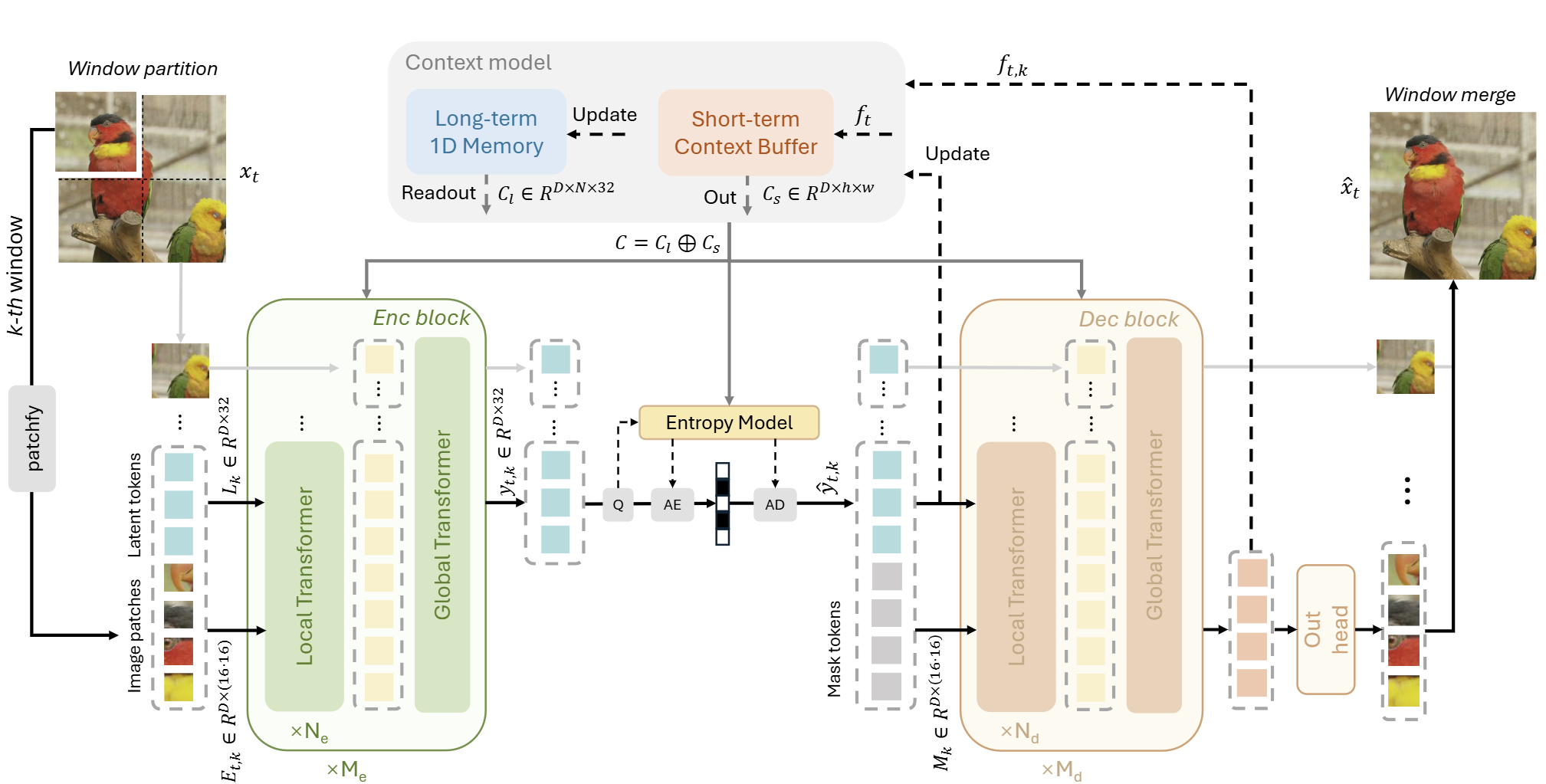
Our method encodes the current frame into a few 1D latent tokens by leveraging both the short- and long-term context. We first employ a Vision Transformer-based encoder to encode the current frame into a few 1D latent tokens. Next, we perform entropy coding in these 1D latent tokens to achieve efficient compression. Finally, these 1D latent tokens are decoded to reconstruct the frame. All three stages are guided by our context model, which integrates two types of context: long-term context from previous 1D latent tokens and short-term context from the preceding frame.
Video Compression Performance
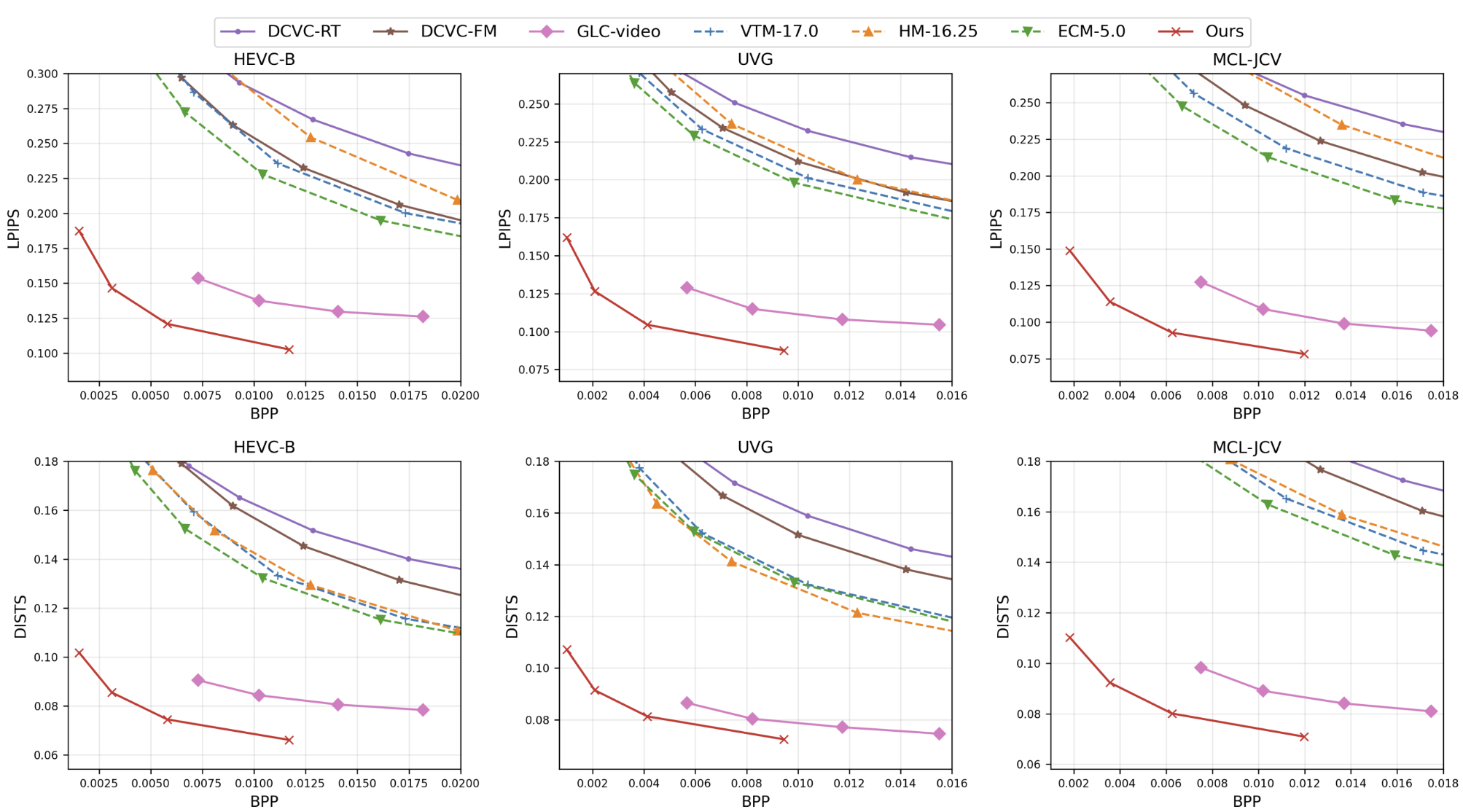
We evaluate our model on the HEVC-B, UVG, and MCL-JCV datasets under low-delay encoding settings (intra-period=–1) in the RGB colorspace.
Visual Comparison
Below, we present image-based visual comparisons between GVC1D and competing methods.

Below, we present video-based visual comparisons between GVC1D and competing methods.




Complexity Analysis
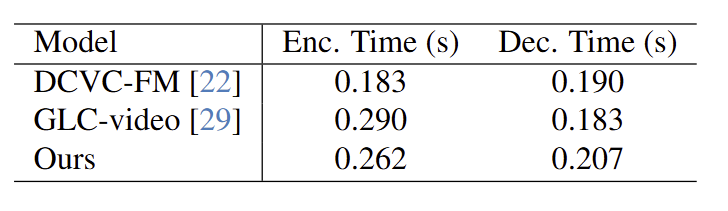
Complexity analysis using fp16 precision at 1080P resolution on an NVIDIA A100 GPU.
Compared with GLC-Video, our method attains a similar overall coding speed, with the encoding even slightly faster, while delivering notably higher visual quality. This efficiency stems from performing compression in a compact latent space with fewer tokens, utilizing a parallel window processing design, and employing advanced techniques such as FlashAttention to accelerate computation.
Citation
If you find this work useful for your research, please cite:
Coming soon.